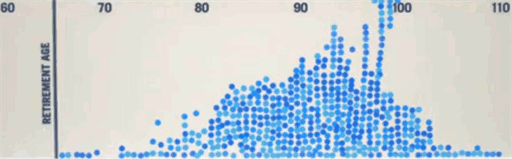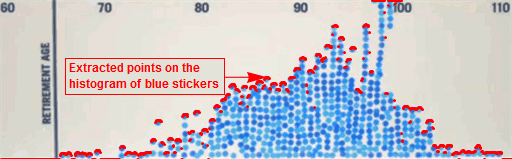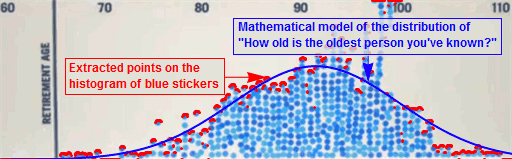
Riding on the wave of a new movement requires that you learn
new skills. I am often asked “What do I need to learn to profit from the Big
Data trend?” My answer is “Learn some Machine Learning.”
Why do I say that? Three reasons
- For business leaders, investing just a little bit of time to pick up the basics of machine learning can help them formulate solvable problems and navigate the sea of potential technological options that can be used to realize business value
- Those with even a basic degree of comfort with numbers (high school math, really) can quickly come up to speed on machine learning and go on to become leaders who contribute to gains on hundreds of challenging real-world data analysis problems from a wide span of industries and sciences.
- They are hiring. Do you have the skills? More and more companies are looking at data to increase productivity and competitiveness. What are you waiting for?
Machine Learning has arrived
After all, no less an authority than Bill Gates recently
said, “When it comes to technology, there are four areas where I think a lot of
exciting things will happen in the coming decades: big data, machine learning,
genomics, and ubiquitous computing …” What is more, Bill Gates is also reported
to have declared that “a breakthrough in machine learning would be worth ten
Microsofts.”
Even if you happen to think that the above stand is
debatable, there is no question that machine learning has arrived and is moving
center stage. Large computational capital is readily available, and simple
algorithms are waiting for someone to leverage them for handsome returns.
Numerous aspects of our life, both significant and trivial,
have become incredibly measurable. Several aspects are already finely measured
and stored. Privacy concerns aside, this might seem like a good thing till we
realize that most of this data lies in deep slumber. Unused, unsorted and
unedited, this data, rather than boosting the bottom line, kills productivity –
cluttering up storage space on devices and slowing down connections. Just as
most of us store more digital pictures than we can handle, companies frequently
find that – although a treasure troves of data is on hand – the very volume of
data makes it difficult to find what they need or glean actionable insight.
But we mustn’t blame the data. We must celebrate it. Astute
business leaders have realized that tremendous insights exist in Big Data and
want to use it in order to leap ahead of their competitors. Businesses are
looking for expertise in machine learning to parse, reduce, simplify and
categorize data.
Practitioner of this craft, sometimes called data
scientists, are not quite software engineers. Although they might be quite
competent at coding, their expertise lies in developing or adapting algorithms
that operate on data to reveal order that can lead to insight. Data scientists
can understand a data-centric problem, come up with a solvable formulation and
recommend a practical solution. They may provide working prototypes to
demonstrate the solution, and even sometimes provide segments of final code.
They work closely with others more grounded in software engineering whose job
is to translate their work, optimize it exquisitely and plug it into the larger
framework of efficient runtime code implemented in the final product.
You are already a Data Scientist
Lest we forget, the ability to tame Big Data is the ultimate
hallmark of intelligent beings. Your brain runs the best machine learning
algorithms known. It absorbs massive data sets every moment of every day. The
processing and directing of thought and action that you so effortlessly
accomplish is amazing. Even more so once you consider that no neuron in your
brain fires faster than 1 kHz, the speed of a circa 1980 PC. Of course, your
brain’s biological computing system does not work the way a computer does.
Rather than laboriously finding and opening large files loaded with complex
information, your brain calls up millions of individually stored simple data
elements, processes them in parallel in multiple locations, sometimes breaks
rules leading to profoundly creative solutions and generally causes an
emergence of sensible outcomes. This happened even before you spoke your first
word, and now happens even when you sleep.
So, it looks like we already know machine learning without
knowing that we know it. Many practitioners that I know report that the process
of learning machine learning is accompanied by fleeting feelings of
understanding how we think. This seems natural considering that machine
learning is all about the problem of finding essential and distinguishing
properties of a category, a quest that we are constantly engaged in.
Just good for fun and games?
Let me end this blog by taking another question that I am
sometimes asked, “Is Big Data only useful for superficial stuff like
recommending good movies to watch?”
My answer is that machine learning is used in several
efforts to improve the quality of security, public health and safety. Methods
for the automatic detection of events and other patterns in huge data sets find
natural applications in areas such as flagging shipping containers likely to
hold banned goods, timely alarms of disease outbreaks, warning of possible but
yet-to-be-committed crimes, predicting dangerous sinkholes using satellite
data, improved methods of assessing a patient’s risk of developing diabetes,
proactively abating traffic congestion, early detection and containment of
forest fires before they become too big, the list goes on ...
To be sure, Big Data and machine learning will be used to
earn big bucks for corporations. But it is being, and can be, put to more noble
uses in the wider world.